Legacy ETL platforms have a dirty secret: they validate data constantly, but they do it invisibly. A SAS DATA step that reads a column as numeric will silently reject non-numeric rows. An Informatica mapping with a NOT NULL connected port will drop records that violate the constraint. A DataStage job with a reject link will route bad data to a file that nobody checks. These implicit validation behaviors become muscle memory for the teams that depend on them — and they vanish completely when the code is migrated to dbt.
This article covers how to build a comprehensive dbt testing strategy that replaces the implicit safety nets of legacy ETL with explicit, version-controlled, automated assertions. Whether you are migrating from SAS, Informatica, DataStage, BTEQ, or any other legacy platform, the testing patterns described here will catch the regressions that migration inevitably introduces.
1. Why Testing Matters More After Migration
In a greenfield dbt project, testing is important. After a migration, it is essential. The reason is straightforward: you are not just building new pipelines — you are replicating the behavior of existing pipelines that production systems depend on. Every downstream report, every dashboard, every regulatory filing expects specific data shapes, value ranges, and row counts. A migration that produces different results, even subtly, is a failed migration.
Legacy platforms embedded validation logic in layers that are easy to overlook during conversion:
- Column types enforced at read time. SAS formats and informats enforce type constraints the moment data enters a
DATAstep. Informatica port datatypes reject incompatible values before transformation logic executes. In dbt, all data is already in the warehouse — type enforcement happens at the SQL level or not at all. - Implicit deduplication. Many legacy jobs use
PROC SORT ... NODUPKEYin SAS orDISTINCTin intermediate staging steps that are so routine they are not documented. If the migration misses one, duplicate rows propagate downstream. - Reject handling as validation. DataStage reject links and Informatica error rows silently removed bad data. In dbt, there is no reject mechanism — if bad data exists in the source, it flows through unless a test catches it.
- Hard-coded business rules. Legacy code often contains validation logic embedded in conditional statements:
IF amount < 0 THEN amount = 0;in SAS, or filter transformations in Informatica that exclude invalid records. These rules must be preserved as dbt tests or model logic.
The core insight is this: legacy platforms validated data as a side effect of processing it. dbt separates validation from transformation entirely. Tests are independent SQL queries that assert conditions about the output of models. This separation is architecturally superior — but it means you must explicitly define every validation that was previously implicit.

dbt — enterprise migration powered by MigryX
2. Schema Tests: The First Line of Defense
dbt schema tests are declared in YAML files alongside model definitions. They are the simplest and most maintainable form of testing, and they should be the first thing you define for every model in a migrated project.
The Four Built-in Schema Tests
dbt ships with four schema tests that cover the most common data integrity assertions:
unique— Asserts that a column contains no duplicate values. This replaces the implicit uniqueness guarantees that legacy primary keys,PROC SORT NODUPKEY, and DataStageRemove Duplicatesstages provided.not_null— Asserts that a column contains no NULL values. This replacesNOT NULLconstraints in legacy DDL, Informatica port-level null handling, and SASMISSINGfunction checks.accepted_values— Asserts that every value in a column belongs to a defined set. This replaces SAS format-based validation, Informatica lookup-based filtering, and DataStage constraint checks.relationships— Asserts referential integrity between two models. This replaces foreign key constraints that the legacy database enforced and that the warehouse (especially Snowflake and BigQuery) does not enforce at runtime.
A typical schema test definition in schema.yml looks like this:
models:
- name: fct_claims
columns:
- name: claim_id
tests: [unique, not_null]
MigryX auto-generates comprehensive schema tests for every migrated model, covering uniqueness, nullability, accepted values, and referential integrity based on legacy metadata.
Compound Uniqueness
Compound uniqueness tests catch deduplication issues that simple column-level tests miss. Many legacy tables use composite keys — SAS BY statements and DataStage key columns often define uniqueness across multiple columns — and the dbt-utils package provides a unique_combination_of_columns test for exactly this pattern.
For every migrated model, you should define schema tests that mirror the constraints the legacy system enforced. This is not optional post-migration polish — it is a core deliverable of the migration itself.
MigryX Validation: Zero-Risk Migration
The number one fear in any migration is silent data discrepancies — numbers that look right but are subtly wrong. MigryX eliminates this risk with automated parallel validation. It runs both legacy and converted code against the same input data, then compares outputs row-by-row and column-by-column. Discrepancies are flagged with root cause analysis pointing to the exact transformation that diverged.
3. Data Tests: Business Logic Validation
Schema tests verify structural integrity. Data tests verify that the business logic embedded in your models produces correct results. In dbt, a data test is a SQL query stored in the tests/ directory that returns rows when an assertion is violated. If the query returns zero rows, the test passes.
Row Count Comparisons
Data tests compare row counts, aggregates, and distributions between legacy and migrated outputs, with configurable tolerance thresholds. MigryX auto-generates these validation queries based on legacy-validated baseline values.
Cross-Model Consistency
Cross-model consistency tests verify that related models reconcile — for example, that a summary model's totals match the detail model it aggregates, or that every foreign key in a fact table exists in the referenced dimension. These tests catch the subtle regressions that row counts alone miss.
Data tests are the migration team's safety net. They encode the expected behavior of the legacy system and assert that the new dbt models reproduce it. Build them early, run them continuously, and treat any failure as a migration defect that must be resolved before go-live.
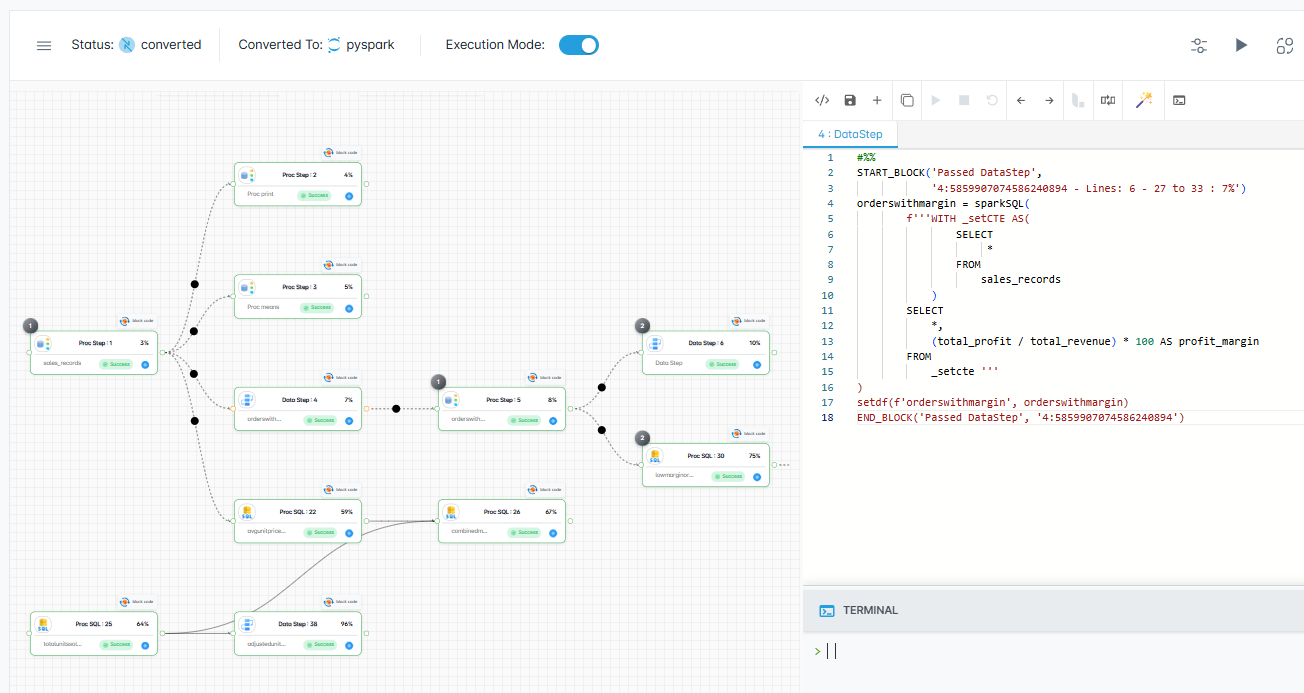
MigryX visual execution tracking confirms every transformation produces identical results
Continuous Validation Throughout the Migration with MigryX
MigryX does not treat validation as a one-time gate at the end of migration. Its validation framework runs continuously throughout the conversion process — catching issues at the individual program level before they compound across dependent pipelines. Teams using MigryX report finding and fixing data discrepancies 10x faster than manual testing approaches.
4. Custom Generic Tests: Reusable Parameterized Assertions
Schema tests and data tests cover most needs, but migration projects often encounter recurring patterns that benefit from reusable test logic. dbt custom generic tests fill this gap. A generic test is a Jinja-templated SQL macro that accepts parameters, making it reusable across many models and columns.
Custom generic tests — reusable validation patterns like range checks, referential integrity, and parent-child consistency — form the final layer. MigryX generates these based on the business rules embedded in your legacy code.
5. Source Freshness Checks
Testing the data inside your models is necessary but not sufficient. You also need to verify that the data feeding your models is current. Stale source data produces correct-looking but outdated results — a particularly dangerous failure mode because dashboards will display without errors while silently showing yesterday's (or last week's) data.
dbt source freshness checks monitor when upstream tables were last updated. You define freshness thresholds in your sources.yml:
Source freshness monitoring ensures upstream data feeds remain current after migration. MigryX configures freshness thresholds based on the legacy system's expected refresh cadence, so stale data is flagged before it corrupts downstream results.
Why This Matters After Migration
Legacy ETL platforms typically ran as monolithic scheduled jobs. If the upstream extract failed, the entire job failed visibly. In the modern ELT stack, ingestion and transformation are decoupled. Fivetran or Airbyte loads data on one schedule; dbt transforms it on another. If the ingestion pipeline silently fails, dbt will happily transform stale data and report success. Source freshness checks close this gap.
For migrated pipelines, configure freshness checks for every source table that the legacy system consumed. Match the thresholds to the legacy system's expected refresh frequency: if the legacy job ran daily, set error_after to 36 or 48 hours to allow buffer for weekends and holidays.
Putting It All Together: A Post-Migration Testing Checklist
A comprehensive post-migration testing strategy layers all four testing mechanisms:
- Schema tests on every model —
uniqueandnot_nullon primary keys,accepted_valueson categorical columns,relationshipson foreign keys. - Data tests for migration validation — Row count comparisons, aggregate reconciliation, and cross-model consistency checks against legacy-validated outputs.
- Custom generic tests for recurring patterns — Date ranges, value ranges, and parent-child count consistency applied across the entire project.
- Source freshness checks on every upstream table — Ensuring that stale ingestion data does not silently corrupt downstream results.
Run all tests as part of every dbt build. In production, a failing test should halt downstream model execution to prevent bad data from propagating. In CI/CD, tests run against pull requests so that migration regressions are caught during code review, not after deployment.
MigryX Auto-Generated Tests
MigryX auto-generates dbt schema.yml with tests inferred from legacy metadata — NOT NULL constraints, primary keys, foreign keys, and value ranges extracted from SAS formats, DataStage column definitions, and Informatica mappings. The result is a comprehensive test suite that mirrors the validation behavior of the legacy system from day one, without manual YAML authoring.
Migration is not complete when the code compiles. It is complete when every model is tested, every source is monitored, and the dbt project produces results that match the legacy system's validated outputs. A rigorous testing strategy is what separates a successful migration from a migration that passes dbt run but fails in production.
Why MigryX Validation Changes Everything
The challenges described throughout this article are exactly what MigryX was built to solve. Here is how MigryX transforms this process:
- Automated parallel testing: MigryX runs legacy and modern code side-by-side, comparing every output automatically.
- Root cause analysis: When discrepancies are found, MigryX pinpoints the exact transformation responsible.
- Continuous validation: Issues are caught per-program during conversion, not discovered in UAT months later.
- Stakeholder confidence: Auditable validation reports prove output parity to business owners and regulators.
MigryX combines precision AST parsing with Merlin AI to deliver 99% accurate, production-ready migration — turning what used to be a multi-year manual effort into a streamlined, validated process. See it in action.
Ready to migrate with confidence?
See how MigryX generates production-ready dbt projects with comprehensive tests built in from the start.
Schedule a Demo